 <
<18
NovemberElastic Search
Description
OVERVIEW OF ELASTIC SEARCH
At its core, we can think of Elasticsearch as a server that can process JSON request and give you back JSON data.Elasticsearch is a distributed, open-source search and analytics engine built on Apache Lucene and developed in Java.Elasticsearch allow you to store, search, and analyze huge volumes of data quickly and in near real-time and give back answer in millisecond. It’'s able to achieve fast search response because instead of searching the text directly, it searches an index. It uses a structure based on document instead of tables and schemas and comes with extensive REST APIs for storing and searching the data.
Elasticsearch is a distributed, free and open search and analytics engine for all types of data, including textual, numerical, geospatial, structured, and unstructured. Elasticsearch is built on Apache Lucene and was first released in 2010 by Elasticsearch N.V. (now known as Elastic).
Inverted index in Elasticsearch
Inverted index will help you understand the limitations and strengths of Elasticsearch compared with the traditional database systems out there. Inverted index at the core is how Elasticsearch is different from other NoSQL stores, such as MongoDB, Cassandra, and so on.Without the inverted index, the application has to go through each web page and check whether the word exists in the web page. An inverted index is similar to the following table. It is like a map with the term as a key and list of the documents the term appears in as value.
| Term | Document |
| Java | 1 |
| Information | 1,2 |
| Technology | 2,3 |
| Visit | 3 |
| Microservices | 1,2,3 |
Once we construct an index, as shown in above table, to find all the documents with the term Java is now just a lookup. Just like when a library gets a new book, the book is added to the card catalog, we keep building an inverted index as we encounter a new web page. The preceding inverted index takes care of simple use cases, such as searching for the single term. But in reality, we query for much more complicated things, and we don’t use the exact words.
Scalability and availability in Elasticsearch
Let’s say you want to index a billion documents; having just a single machine might be very challenging. Partitioning data across multiple machines allows Elasticsearch to scale beyond what a single machine do and support high throughput operation. Your data is split into small parts called shards. When you create an index, you need to tell Elasticsearch the number of shards you want for the index and Elasticsearch handles the rest for you. As you have more data, you can scale horizontally by adding more machines. We will go in to more details in the sections below.
There are type of shards in Elasticsearch – primary and replica. The data you index is written to both primary and replica shards. Replica is the exact copy of the primary. In case of the node containing the primary shard goes down, the replica takes over. This process is completely transparent and managed by Elasticsearch. We will discuss this in detail in the Failure Handling section below. Since primary and replicas are the exact copies, a search query can be answered by either the primary or the replica shard. This significantly increases the number of simultaneous requests Elasticsearch can handle at any point in time.As the index is distributed across multiple shards, a query against an index is executed in parallel across all the shards. The results from each shard are then gathered and sent back to the client. Executing the query in parallel greatly improves the search performance.
Cluster
An Elasticsearch cluster is a group of one or more node instances that are connected together. The power of an Elasticsearch cluster lies in the distribution of tasks, searching, and indexing, across all the nodes in the cluster.
Node
A node is a single server that is a part of a cluster. A node stores data and participates in the cluster’s indexing and search capabilities. An Elasticsearch node can be configured in different ways:
Master Node — Controls the Elasticsearch cluster and is responsible for all cluster-wide operations like creating/deleting an index and adding/removing nodes.
Data Node — Stores data and executes data-related operations such as search and aggregation.
Client Node — Forwards cluster requests to the master node and data-related requests to data nodes.
Shards
Elasticsearch provides the ability to subdivide the index into multiple pieces called shards. Each shard is in itself a fully-functional and independent “index” that can be hosted on any node within a cluster. By distributing the documents in an index across multiple shards, and distributing those shards across multiple nodes, Elasticsearch can ensure redundancy, which both protects against hardware failures and increases query capacity as nodes are added to a cluster.
Replicas
Elasticsearch allows you to make one or more copies of your index’s shards which are called “replica shards” or just “replicas”. Basically, a replica shard is a copy of a primary shard. Each document in an index belongs to one primary shard. Replicas provide redundant copies of your data to protect against hardware failure and increase capacity to serve read requests like searching or retrieving a document.
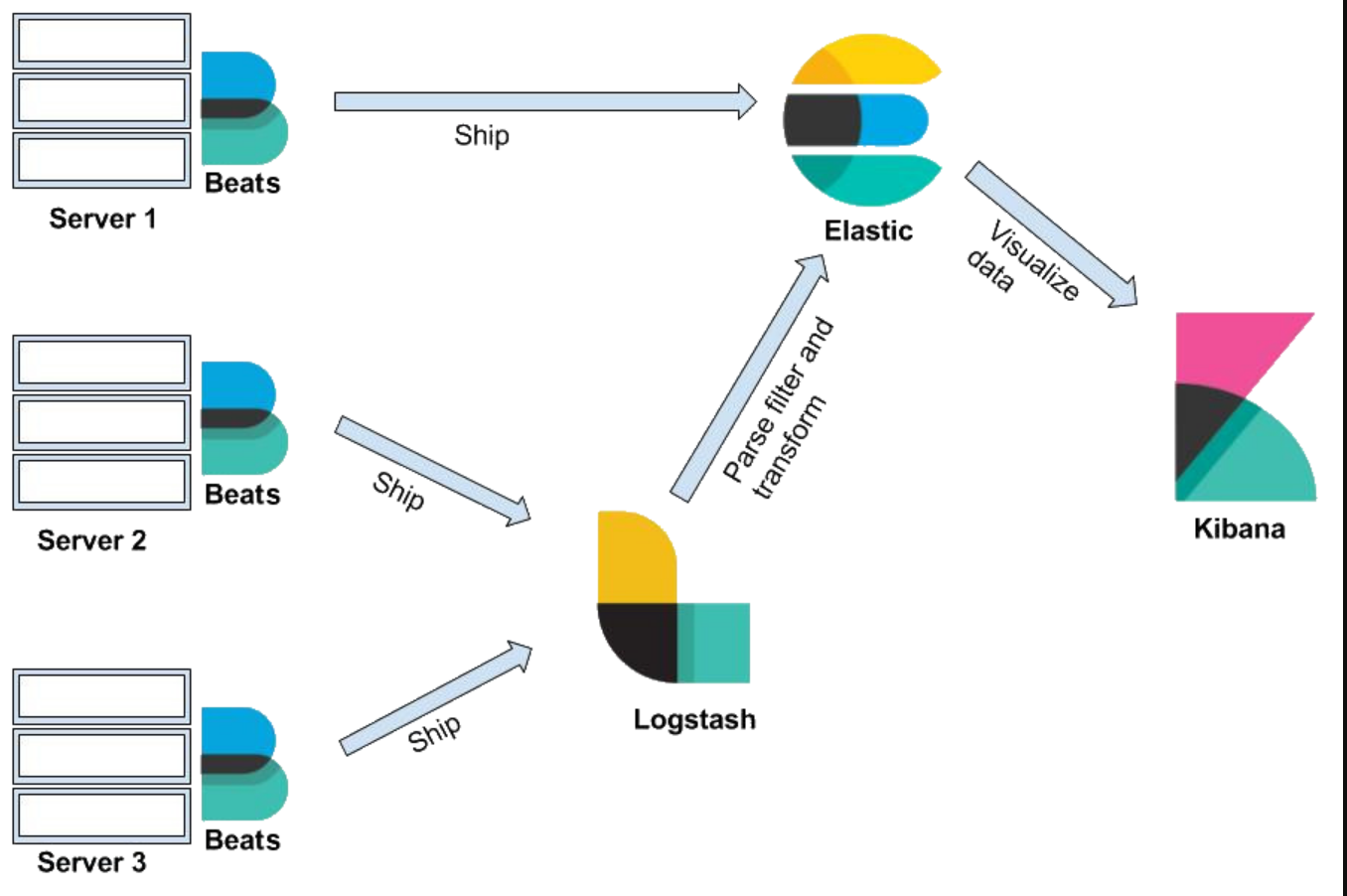
The Elastic Stack (ELK)
Elasticsearch is the central component of the Elastic Stack, a set of open-source tools for data ingestion, enrichment, storage, analysis, and visualization. It is commonly referred to as the “ELK” stack after its components Elasticsearch, Logstash, and Kibana and now also includes Beats. Although a search engine at its core, users started using Elasticsearch for log data and wanted a way to easily ingest and visualize that data.
Kibana
Kibana is a data visualization and management tool for Elasticsearch that provides real-time histograms, line graphs, pie charts, and maps. It lets you visualize your Elasticsearch data and navigate the Elastic Stack. You can select the way you give shape to your data by starting with one question to find out where the interactive visualization will lead you. For example, since Kibana is often used for log analysis, it allows you to answer questions about where your web hits are coming from, your distribution URLs, and so on. If you’re not building your own application on top of Elasticsearch, Kibana is a great way to search and visualize your index with a powerful and flexible UI. However, a major drawback is that every visualization can only work against a single index/index pattern. So if you have indices with strictly different data, you’ll have to create separate visualizations for each. For more advanced use cases, Knowi is a good option. It allows you to join your Elasticsearch data across multiple indexes and blend it with other SQL/NoSQL/REST-API data sources, then create visualizations from it in a business-user friendly UI.
Logstash
Logstash is used to aggregate and process data and send it to Elasticsearch. It is an open-source, server-side data processing pipeline that ingests data from a multitude of sources simultaneously, transforms it, and then sends it to collect. It also transforms and prepares data regardless of format by identifying named fields to build structure, and transform them to converge on a common format. For example, since data is often scattered across different systems in various formats, Logstash allows you to tie different systems together like web servers, databases, Amazon services, etc. and publish data to wherever it needs to go in a continuous streaming fashion.
Beats
Beats is a collection of lightweight, single-purpose data shipping agents used to send data from hundreds or thousands of machines and systems to Logstash or Elasticsearch. Beats are great for gathering data as they can sit on your servers, with your containers, or deploy as functions then centralize data in Elasticsearch. For example, Filebeat can sit on your server, monitor log files as they come in, parses them, and import into Elasticsearch in near-real-time.